Logistic
Regression
Fitting binary regression models is done via
maximum likelihood estimation.
We can use the Binomial probability and maximise
the log likelihood, or by minimising the negative loglikelihood.
|
|
To
find the gradients, we use backpropagation!
|
|
We
also need to derive the gradients for each possible activation function.
|
Activation |
Function |
Pointwise Derivative |
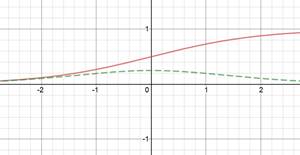
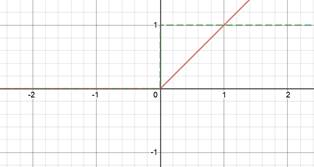
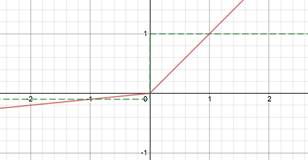
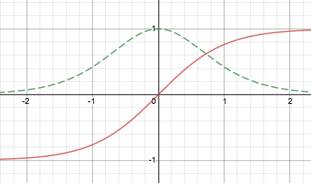
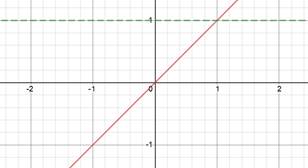
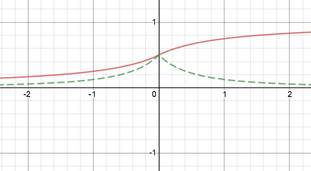
Red is function. Green derivative. |
|
Sigmoid |
|
|
|
|
ReLU |
|
[Note, since ReLU is positive, can test
equality = 0] |
|
|
Leaky ReLU [Can change 0.01] |
|
|
|
|
Tanh |
|
|
|
|
Linear |
|
|
|
|
Sigmoid Softsign [Approximate Sigmoid] |
|
|
|
By
computing gradients backwards in the chain, we then can derive the gradients
for each weight and bias.
|
|
Copyright Daniel Han 2024. Check out Unsloth!