Adam, AdamW Optimizers
The most popular optimizer in neural networks is
the Adam Optimizer.
https://arxiv.org/abs/1412.6980 [Adam:
A Method for Stochastic Optimization (2014)]
It combines momentum and scales the learning rate
separately for each parameter like RMSProp.
https://arxiv.org/pdf/1711.05101.pdf
[Decoupled Weight Decay Regularization (2019)]
extends Adam by incorporating L2 Regularization and weight decay.
|
|
Adam also performs bias correction to discount early on updates.
|
|
![]() is
the gradient,
is
the gradient, ![]() is
the momentum term,
is
the momentum term, ![]() is
the RMSProp term.
is
the RMSProp term.
![]() is
the learning rate,
is
the learning rate, ![]() is
the learning rate scheduler, which can be set to 1 or not.
is
the learning rate scheduler, which can be set to 1 or not.
![]() is
the regularization parameter.
is
the regularization parameter.
Typical values for parameters include
|
|
Notice
how we can simplify the update equation by bringing the divisor out.
|
|
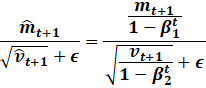
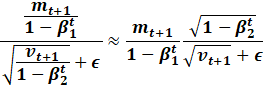
Likewise, to take advantage of the fast reciprocal square root,
we need to fuse the epsilon term.
Notice
how we first prove the triangle inequality.
|
|
So,
by storing variables in memory, we have that
|
|
Also, notice the exponent ![]() for
bias correction starts from 1 and not 0!
for
bias correction starts from 1 and not 0!
Likewise, notice ![]() is
essentially just
is
essentially just ![]() since
a small number squared is even smaller.
since
a small number squared is even smaller.
Keep ![]() at
machine resolution ie 1e-7 or so for float32.
at
machine resolution ie 1e-7 or so for float32.
So, by using batch gradient
descent, we have the final algorithm:
|
|
Copyright Daniel Han 2024. Check out Unsloth!