RAdam Rectified Adam
The state of the art Rectified Adam optimizer took
the community by storm!
Currently SGD with momentum is used to get the
highest accuracy. Now, RAdam can be used instead!
Essentially for the first 5 or so iterations, RAdam
tries to correct for variance in the updates.
https://arxiv.org/pdf/1908.03265.pdf
[On the Variance of the Adaptive Learning Rate and Beyond (2019)]
https://github.com/LiyuanLucasLiu/RAdam/issues/54 [RAdam
Instability vs AdamW / Adam (2020)]
|
|
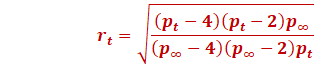
RAdam with weight decay (ie RAdamW) attains much
lower errors than plain AdamW.
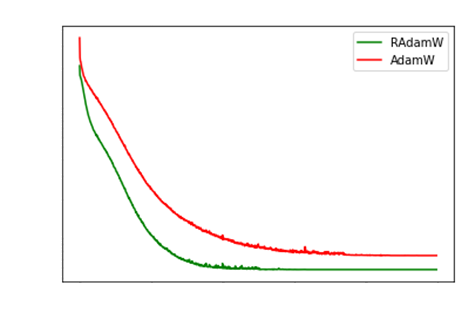
However, in the Bag of Tricks chapter, I said that
RAdam was very unstable when data is not standardized.
The authors say this is due to SGD with Momentum
going haywire. Their fix is to NOT update the parameters
for 5 iterations, and then update.
|
|
Sadly, the fix works, yes. However, the final error
attained seems to be mostly always higher.
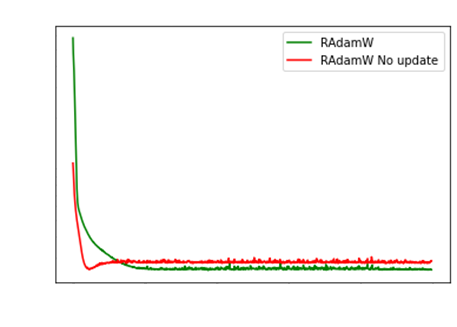
Rather my heuristic to use RAdamW with no
degenerated SGDM is by checking 1 batch’s statistics.
Ie, we check that the second moment is always
generally LESS than the first moment.
So, if the norm(first moment) / mean(second moment)
exceeds 1, then use RAdamW. Otherwise,
use degenerated RAdamW.
|
|
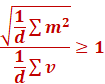
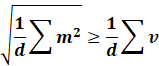
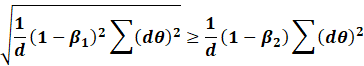
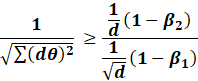
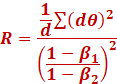
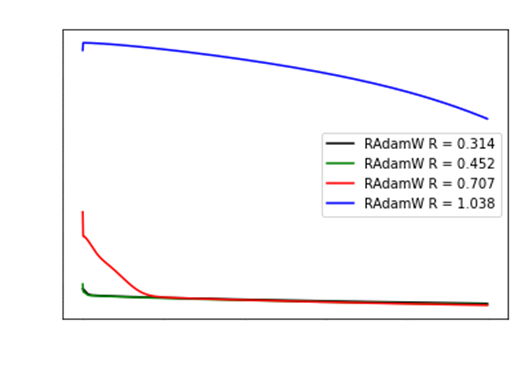
Its clear above that when the ratio is awfully
close to 1, the loss starts diverging.
Likewise, we see when the ratio < 0.5, then
everything seems reasonable.
So our heuristic to use RAdamW is when:
|
|
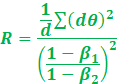
Notice the above heuristic also works to check if
SGD with Momentum can be used or not.
Copyright Daniel Han 2024. Check out Unsloth!