State
of The Art Optimizers
Ranger (FastAI RAdamW + Lookahead) is currently the
fastest optimizer.
By combining LARS / LAMB, RangerLars (or Over9000)
is also used.
However, it has been shown empirically that
RangerLars doesnt achieve good results in the long term.
So, Paratrooper is born!
https://arxiv.org/abs/1907.08610
[Lookahead Optimizer: k steps forward, 1 step back (2019)]
https://youtu.be/TxGxiDK0Ccc [Lookahead
Optimizer: k steps forward, 1 step back | Michael Zhang (2020)]
https://arxiv.org/abs/1712.09913
[Visualizing the Loss Landscape of Neural Nets (2018)]
https://arxiv.org/abs/1904.00962 [Large
Batch Optimization for Deep Learning: Training BERT in 76 minutes (2019)]
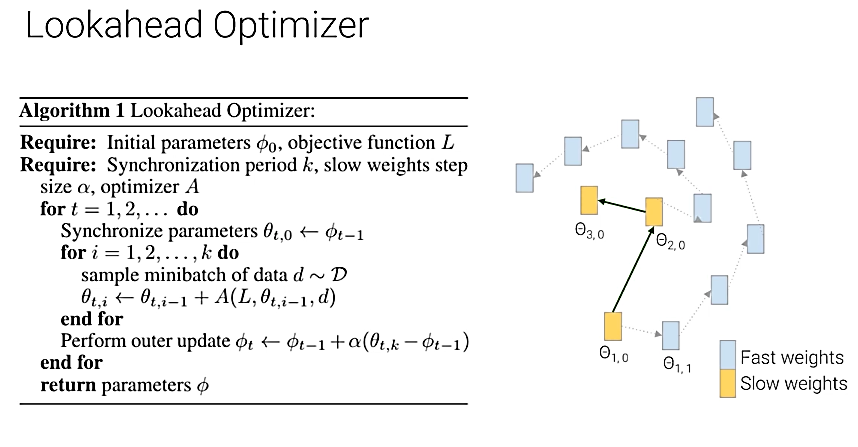
Lookahead
Optimizer
Another optimizer which shocked the community was
the Lookahead optimizer by none other than
the original Adam authors + Geoffery Hinton! FastAI
also showcased the Lookahead optimizer + RAdam (Ranger)
is super fast and now considered the fastest
optimizer in AI!
|
|
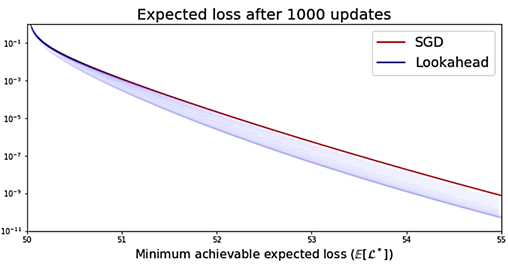
The authors even show the expected loss over many
iterations vs SGDM.
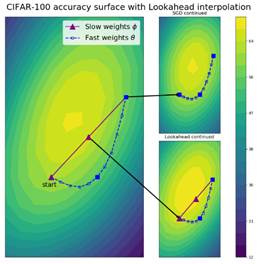
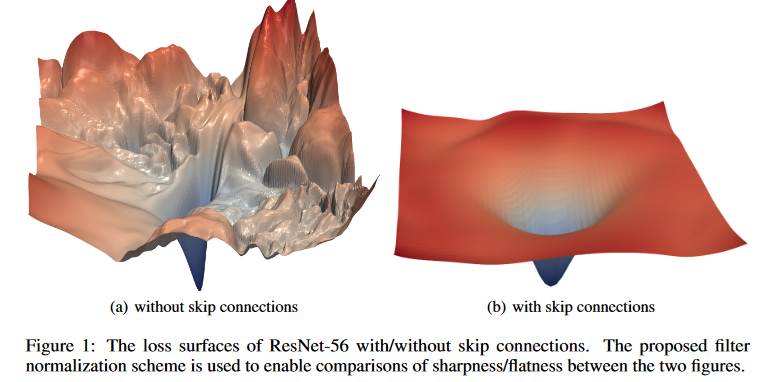
Likewise, Lookahead works since many neural network
landscapes are ironically convex!
Notice convex when skip connections are used. [Ie
use skip connections in deep nets!]
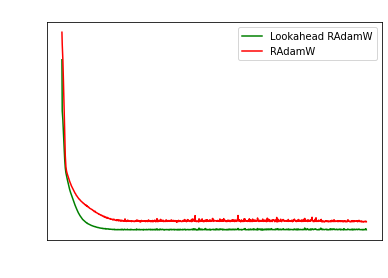
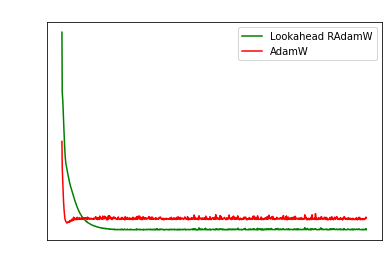
Likewise my own results show Lookahead is super
promising vs plain RAdamW or AdamW.
Ranger
Optimizer
And finally, FastAI s latest advanced optimizer is
the Ranger Optimizer! Essentially, we combine
Lookahead and RAdamW together!
FastAI also showcased that beta1 should be 0.95 and
not 0.9 for better results.
|
|
Results of Ranger are above.
LAMB,
LARS Optimizer
When training neural nets, each layer could require
a different learning rate.
Thats when LAMB / LARS comes along! They compute the
optimum adaptive learning rate
for each layer, and use this to update the final parameters.
Given the Adam Optimizer with weight decay:
|
|
We then compute the layer wise ratio R
|
|
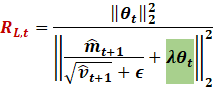
And apply it layer wise
|
|
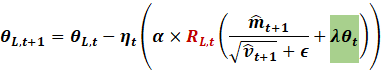
However, LAMB might actually overshoot, and attain
worse accuracy overtime.
So, we have to clamp this ratio (as done in LARS).
|
|
RangerLars
Optimizer
Also known as Over9000 or just RangerLars or
RangerLamb, this optimizer is shockingly good!
(That is, for the first few epochs ☹)
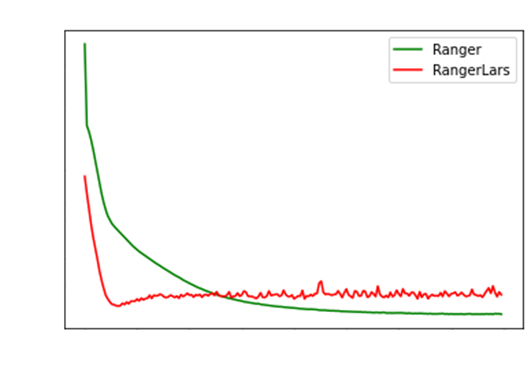
It seems like the clipping down to bring the LARS /
LAMB coefficient down is actually hurting the performance.
Instead of clipping at 0, I found clipping at 1 to
be better.
|
|
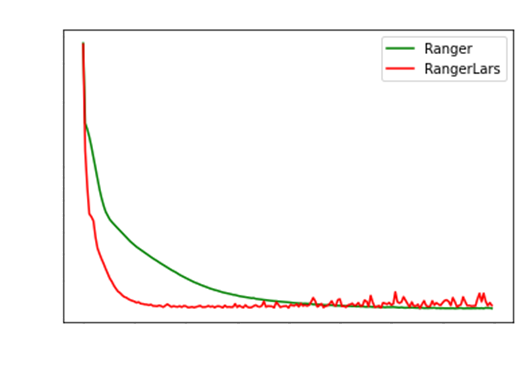
However, RangerLars over many epochs tends to be
extremely noisy.
Sadly, no literature was provided as to alleviate this
issue. The good thing now is that
on just 25 epochs, RangerLars attains the same MSE
as Ranger at 120 epcohs!!!
Thats a massive improvement.
Paratrooper
Optimizer
So, we can alleviate these issues by clipping the
maximum ratio of 10 over time!!
However, we dont just want to create some sort of
hack to attain the maximum ratio.
We can utilise the Adam bias correction term.
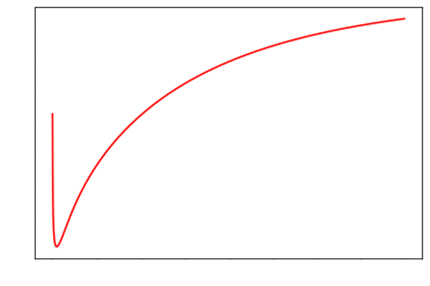
Ie, if we use the reciprocal:
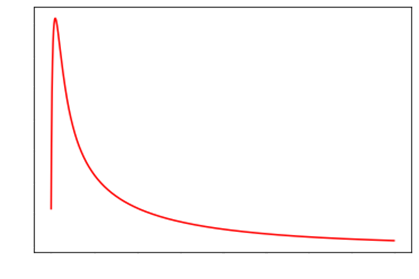
However, it’s still too low. So, we use the RAdam
rectified ratio term in tandem:
|
|
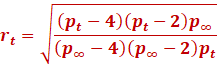
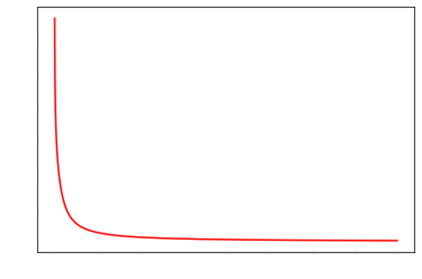
Essentially, over time, the maximum trust ratio
descends to 1, and returns back to being
pure Ranger updates.
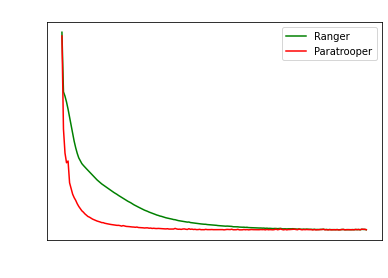
Paratrooper essentially acts like RangerLars for
the first few epochs, then reverts to becoming
Ranger for the last few epochs.
Strangely, Paratrooper attains even LOWER loss then
RangerLars or Ranger, so clearly Paratrooper is a win!
So finally, combined with Ranger: the Paratrooper
final algorithm:
|
|
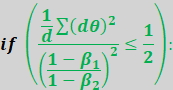
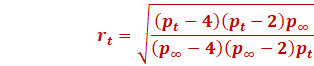
One big advantage of Paratrooper is it fares better
with the reduction of LR on plateau trick.
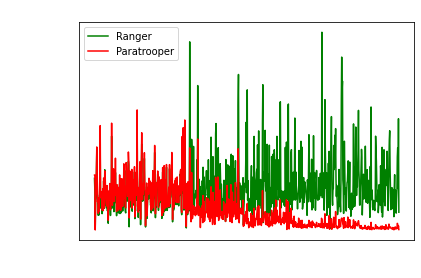
Its pretty clear the steps showcase learning rate
decays when the loss plateaus.
Copyright Daniel Han 2024. Check out Unsloth!