Weight
Initialization
Weight initialization for neural networks is an
active area of research. Common methods include the Glorot
and Xavier initializations, and He’s method.
https://arxiv.org/pdf/1502.01852.pdf
[Delving Deep into Rectifiers : Surpassing Human-Level Performance on ImageNet
Classification (2015)]
http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[Understanding the difficulty of training deep feedforward neural networks
(2010)]
https://arxiv.org/pdf/1312.6120.pdf [Exact
solutions to the nonlinear dynamics of learning in deep linear neural networks
(2014)]
https://arxiv.org/abs/1511.06422 [All
you need is a good init (2015)]
In all papers, people either use Normal or Uniform
initialization. There is a simple relationship:
|
|
To summarize all non-iterative approaches:
|
Activation |
Normal |
Uniform |
|
Sigmoid, Tanh, Linear, Softmax,
Others (Glorot Xavier) |
|
|
|
ReLU, PReLU, ELU derivatives (He) |
|
|
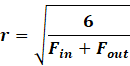
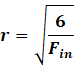
https://github.com/keras-team/keras/issues/52
showcased that using a normal
distribution could in fact reduce accuracy on MNIST
(though a small 0.4%).
For convolutional filters, https://stackoverflow.com/questions/42670274/how-to-calculate-fan-in-and-fan-out-in-xavier-initialization-for-neural-networks,
since each channel gets a filter separately,
|
|
Where ![]() is
the number of channels, and h and w denote the kernel or filter’s height and
weight.
is
the number of channels, and h and w denote the kernel or filter’s height and
weight.
A 3D kernel will just add an extra multiplicative
term.
Another popular method is to use Orthogonal Initialization, where you draw from
a standard normal, then orthogonalize it via
the QR Decomposition. To correct for variance
scaling, the LSUV (Layer
Sequential Unit-Variance Initialization) was proposed.
Using orthogonal initialization, it then corrects
the variance at each layer.
DO NOT use LSUV on Sigmoid, Tanh, Linear, Softmax, Others.
LSUV would fail to converge!
|
LSUV terminates if Sigmoid, Tanh, Linear, Softmax, Others used.
|
LSUV
sadly only improves accuracy by minuscule amounts. In fact, in my own testings,
LSUV actually
makes training worse in the long run!!
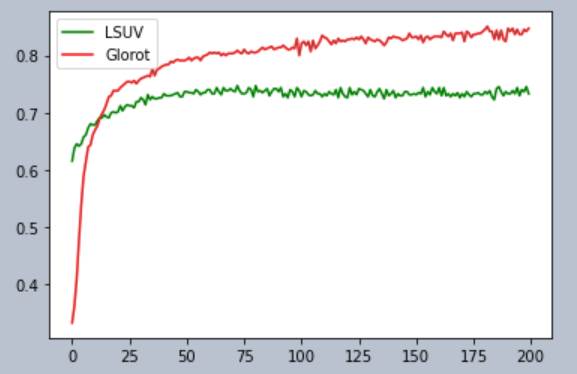
You can see that at the start of training, LSUV actually has
higher accuracies than Glorot. However,
as time goes on, LSUV
has a lower final accuracy than Glorot.
BUT DONT GET FOOLLED!!! MUHAHAHA.
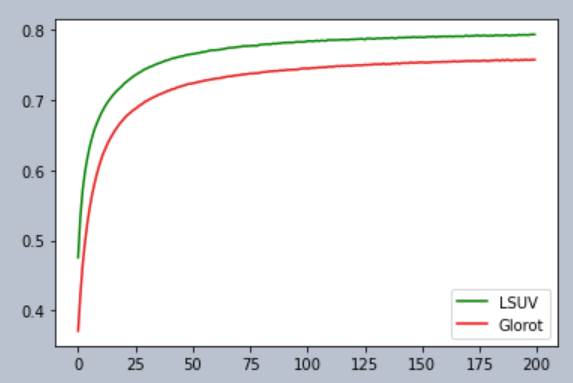
In fact, if you run multiple runs of LSUV and Glorot side by side say for 230
times, each time
randomizing the random seed, we see that LSUV wins!
Copyright Daniel Han 2024. Check out Unsloth!